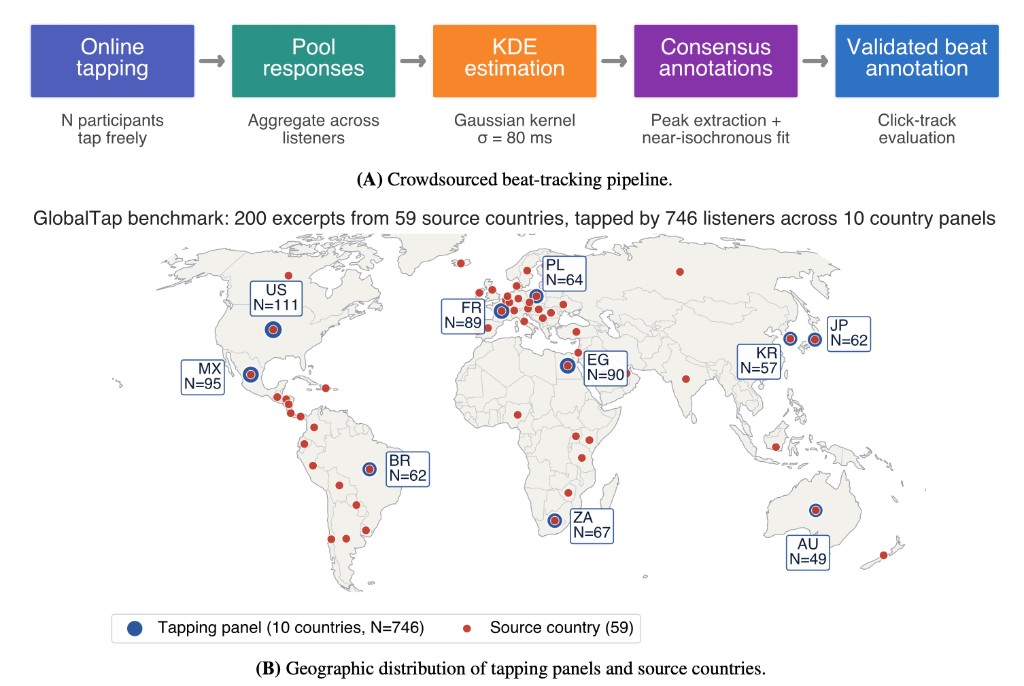
GlobalTap: Globally Diverse Beat Tracking Benchmark
A crowdsourced beat-tracking benchmark spanning 59 countries, built from 1,628 participants tapping to popular music worldwide.
Existing beat-tracking benchmarks draw from a narrow range of musical cultures — predominantly Western — and are difficult to scale due to reliance on expert annotation. GlobalTap addresses both limitations with a 200-excerpt popular-music benchmark spanning 59 countries, developed using a fully scalable online tapping pipeline and data from 1,628 participants recruited across 10 country panels.
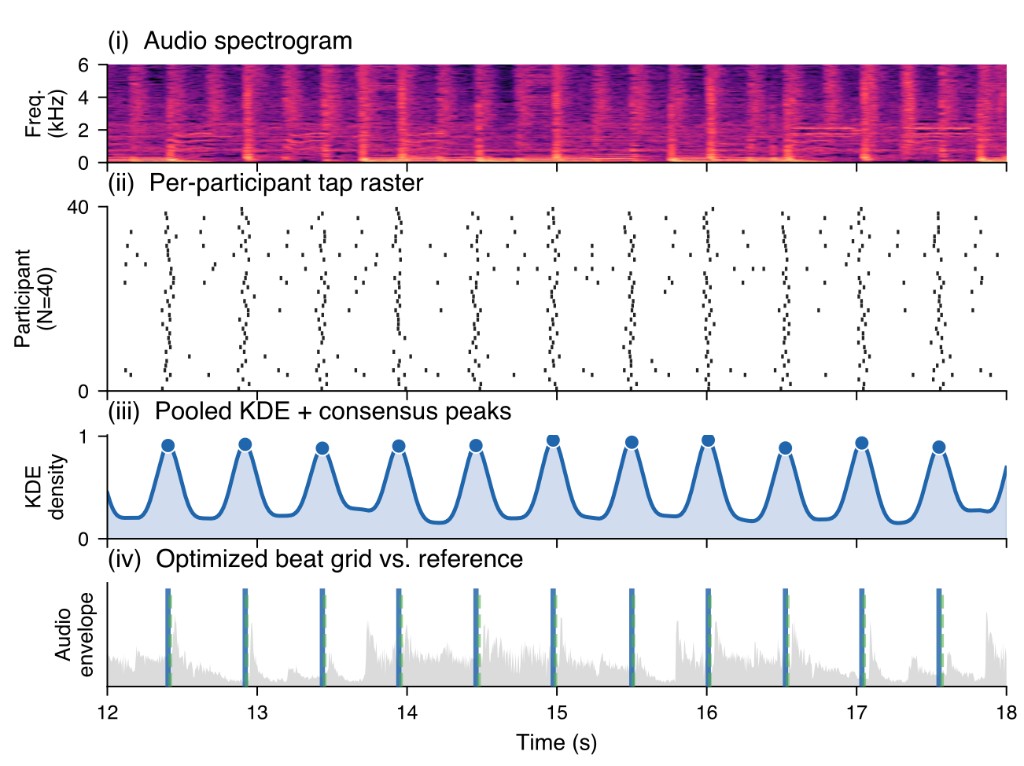
Rather than asking expert annotators to manually place beat times, we collect large pools of tapping responses from online participants using REPP, a high-precision browser-based tool for sensorimotor synchronization experiments. Pooled tap times are smoothed into a density over perceived beat locations using Gaussian kernel-density estimation (σ = 80 ms), and a simple optimization step distills this density into a regularized consensus beat annotation. The resulting crowd-derived annotations are then validated by independent listeners rating click-track overlays.
Validation
A separate listener-rating experiment evaluated the crowd pipeline against 200 existing expert-annotated excerpts. Across all paired excerpts, crowd-derived and expert-reference annotations received statistically indistinguishable ratings (Δ = −0.01, p = .231). On MIREX — where both conditions used the same aggregation pipeline but different tap sources (online crowd vs. lab participants) — ratings were again identical, confirming that online recruitment produces annotations of equivalent quality to those from lab-recruited participants.
Crowd annotations occasionally diverged from expert references in systematic, musically interpretable ways: phase offsets (the crowd often anchored to a perceived acoustic event rather than the theoretically correct beat), tactus-level alternatives (listeners preferring a half- or double-time pulse), and bimodal tapping revealing co-existing metrical interpretations. These structured disagreements expose genuine perceptual ambiguity that single-reference annotations cannot capture.
Case studies
Candombe — phase offset. The crowd anchors to the displaced perceived beat, approximately 85 ms later, corresponding to a salient acoustic event: an emphasized onset by the chico drum. The expert annotation places the beat in accordance with the dance movement, one sixteenth note earlier.
GTZAN Disco — simple alignment. KDE peaks track the optimizer grid throughout the entire window; crowd and reference clicks are perceptually indistinguishable.
What we do
- Collect large-scale online tapping data via REPP and PsyNet, bypassing browser timer jitter for millisecond-precise tap timing.
- Aggregate pooled taps into consensus beat annotations using Gaussian KDE and a near-isochronous grid optimizer.
- Compute intrinsic quality measures (beat-sequence CV and inter-subject tapping coherence, ISTC) that flag perceptually difficult excerpts without requiring an external reference.
- Validate crowd annotations against expert references via a listener-preference experiment with 130 raters across 240 excerpts.
- Release the full benchmark with de-identified tap data, consensus annotations, quality measures, and a reproducible pipeline.
Why it matters
The main obstacle to culturally broader beat-tracking evaluation is not a lack of music, but a lack of scalable annotation methods. Expert annotations are expensive, require specialist musical knowledge, and do not easily transfer across cultural traditions. GlobalTap demonstrates that online crowd tapping can close this gap, producing perceptually valid annotations at scale and across diverse musical styles. By releasing raw tap times alongside consensus beats, the benchmark also makes perceptual ambiguity inspectable — contributing to cognitive research on beat perception as well as to computational modeling and music information retrieval.