One Test Many Tongues
A scalable, corpus-derived vocabulary test for measuring language proficiency across thousands of languages.
Language shapes cognition, social interaction, and cultural experience, but measuring linguistic background at global scale remains difficult. Traditional language proficiency tests are typically hand-crafted by experts, available for only a small number of languages, and hard to deploy efficiently in large online studies.
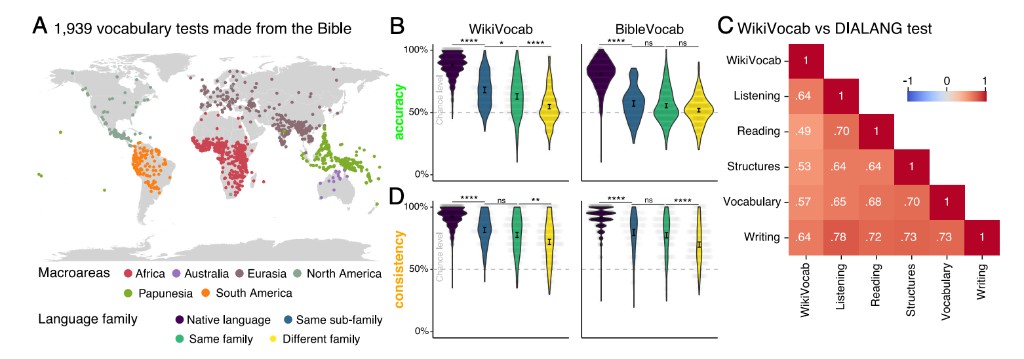
This project develops WikiVocab, an automated pipeline for deriving brief vocabulary tests from text corpora. The method creates matched real-word and pseudoword items, validates them across languages, and makes it possible to estimate first- and second-language proficiency quickly in large, multilingual participant pools.
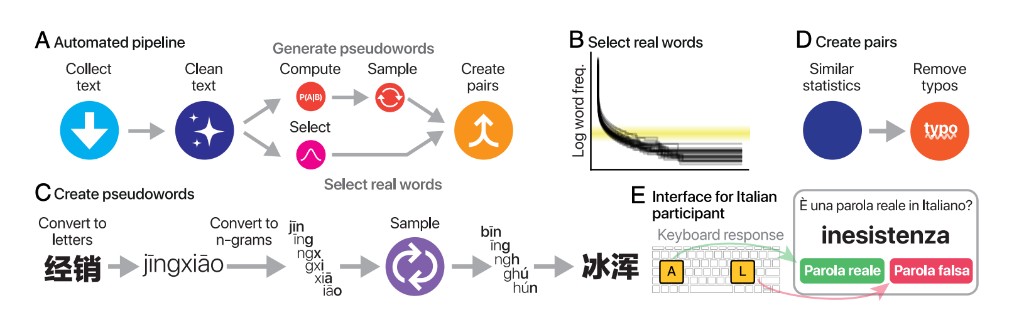
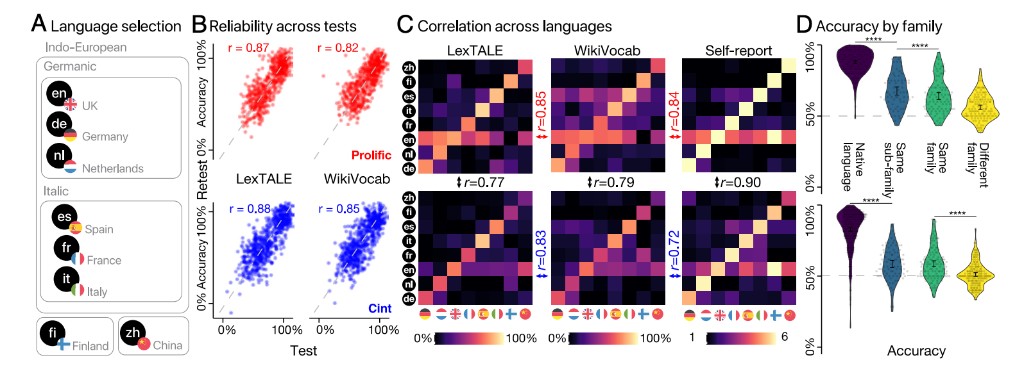
The resulting test is designed to be short enough for online experiments while still distinguishing native speakers, second-language speakers, and nonspeakers. In validation studies, WikiVocab shows high test-retest reliability and strong alignment with existing language tests and self-reported proficiency, while remaining scalable across many more languages than expert-built instruments.
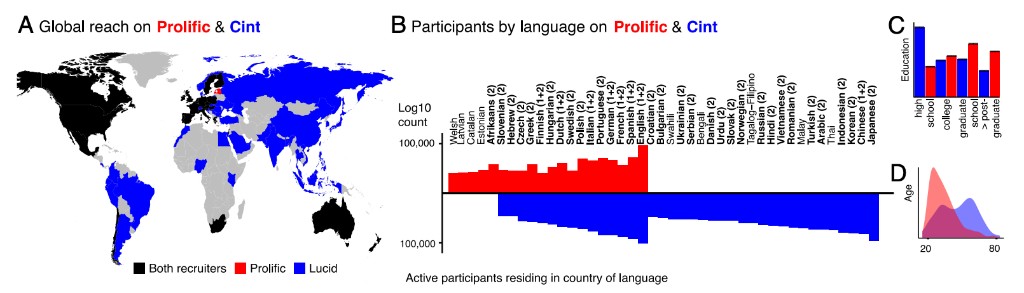
The project also maps the global reach of online recruitment platforms. By comparing Prolific and Cint, the work characterizes which languages and countries can be sampled at scale, and how participant demographics vary across recruitment sources.
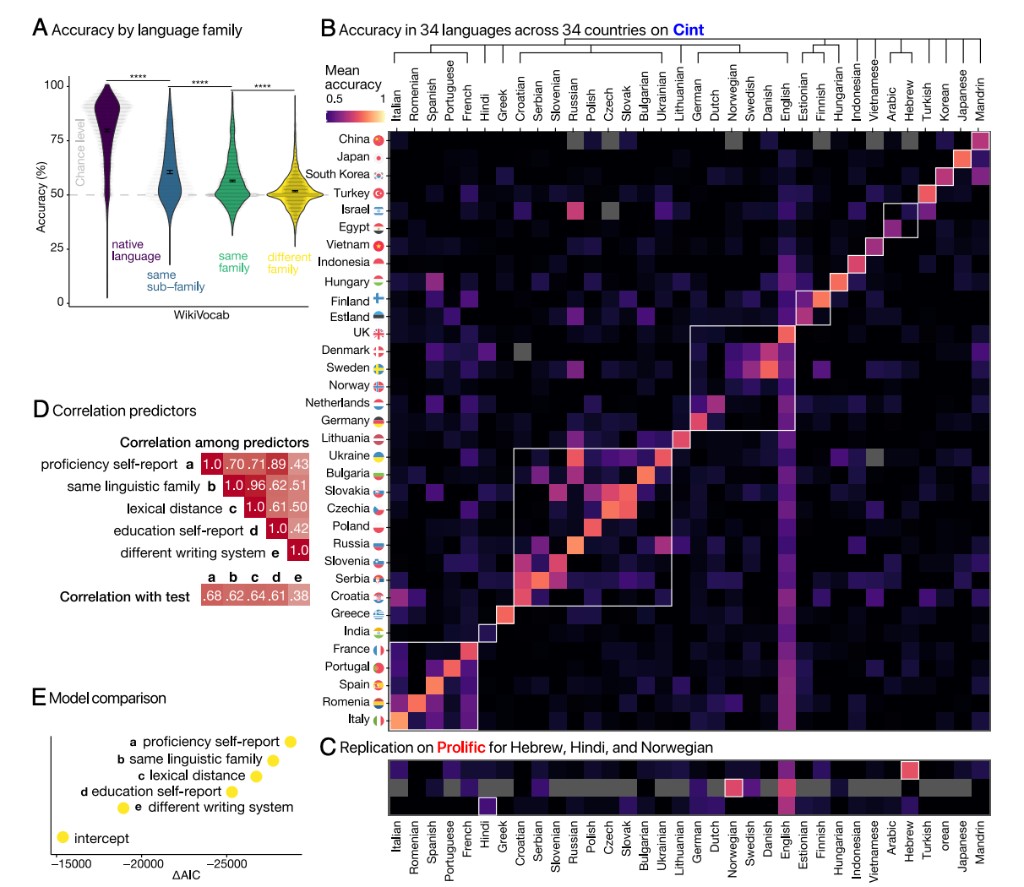
Extending the method to 34 languages across 34 countries reveals structure in global language proficiency. Accuracy is highest for native languages and decreases with linguistic distance, while model comparisons show that self-reported proficiency, linguistic family, lexical distance, education, and writing-system differences all predict performance.
What we do
- Build automated vocabulary tests from large text corpora, making language proficiency measurement scalable beyond expert-built tests.
- Generate matched real-word and pseudoword pairs while controlling low-level lexical statistics and removing near-typos.
- Validate online language tests across recruitment platforms, languages, and participant backgrounds.
- Map the linguistic reach of online participant pools and provide infrastructure for globally distributed cognitive science.
Why it matters
Many large-scale online experiments rely on participants’ language background, but self-report alone is often too coarse for cross-cultural research. WikiVocab provides a fast, objective, and scalable way to measure language proficiency across diverse populations. This supports more rigorous global studies of cognition, language, culture, and human behavior, while helping reduce the field’s overreliance on English-language samples.
Related Publications
2026
-
Proceedings of the National Academy of Sciences, 2026